来源:HIT专家网 记者:陶玲


清华大学统计学研究中心副主任、副教授 邓柯
“在大数据时代,统计学承担着什么样的角色?社会有一种声音认为,统计学已经过时,变得不那么重要,今后大数据分析将逐步代替传统统计人员的工作。其实,在大数据时代,统计学的作用非但没被减弱,反而越来越重要。”3月18日,在由中国研究型医院学会医疗信息化分会医疗和临床科研大数据专业委员会主办、HIT专家网承办的“医疗大数据应用与实践研讨会”上,有着丰富的统计分析、数据处理实战经验以及前沿理论研究背景的清华大学统计学研究中心副主任、副教授邓柯如是认为,并且从统计学的角度给大家分享了最近在医学自然语言处理研发中取得的一些成果和经验。
近几年,清华大学统计中心以数据挖掘、数据建模为核心,做了不少基因组、生物信息、组学数据的分析,也涉猎不少当前热点,如文本分析、医学因果推断研究等。最近,该中心又在自然语言处理方面,提出了一些创新性的统计学模型和方法。
清华大学成立医疗大数据中心
据邓柯副教授介绍,清华大学统计中心研究团队立足于统计学方法,突出信息数据建模,关注信息数据的痛点,希望让理论研究能够真正与实践相结合,搭建起世界一流的统计学科平台,服务于医学等领域。中心虽然成立时间不长,但吸纳了众多海内外高精尖人才,学科、科研功底非常不错,实战分析和国际视野也都具备,可以跟众多企业和机构建立深度实战的合作关系。其中,哈佛大学统计系的刘军教授和哈佛大学生物统计系的林希虹教授担任中心共同主任,两位教授都是华人统计学界非常知名的统计学家。
2015年年底,该中心还成立了医疗大数据中心,旨在整合海量复杂的医疗健康大数据,进行智能处理、信息挖掘,为公众健康、临床决策、疾病诊断和治疗、政府决策提供支持。通过对临床表型与生命组学数据进行整合分析,致力实现对肿瘤、慢性病、罕见病等严重危害我国人民身体健康的高危疾病实现精准预防、诊断和治疗。
“医学数据的维度非常高,有病历、图像、医保数据等。我们希望通过各种各样的分析,发现医疗过程中已存在或潜在的问题,并利用辅助工具手段帮助医疗诊治的开展。”邓柯表示,医疗大数据中有一个很大的痛点:自然语言的处理。通过分析前整合以及统计建模、模型识别等一系列过程,能够帮助信息实现结构化、代码化,让非结构化的数据变成结构化数据。最终,结合相关专业知识加以应用。
然而,医疗数据牵涉到复杂的医学概念、概念关联,很多都是非结构化、非标准化的数据,要达到精细化处理非常困难。为此,邓柯教授所在的团队正在自然语言处理中引入各种统计学方法。
电子病历数据的独特性让传统分析方法失效
以医疗大数据中非常重要的组成部分——电子病历为例。目前,医学科研中简单的文本查询并不能满足临床、科研的需要,但想要做复杂的查询又很难。主要原因在于电子病历所涉及的语言文本非常不易于处理。病历内容庞杂,它包括疾病描述、疾病历史、检验检查等各种格式的数据。同时,医学文本夹杂很多不符合常规语言规范的术语,术语、数据之间关系复杂,提取也很难。医学知识库虽然能起一定作用,但是本身的构建也是难点。
要解决这一难题,必须突破两方面挑战:第一,如何处理海量的医学术语语言;第二,如何让医学文本规范化。
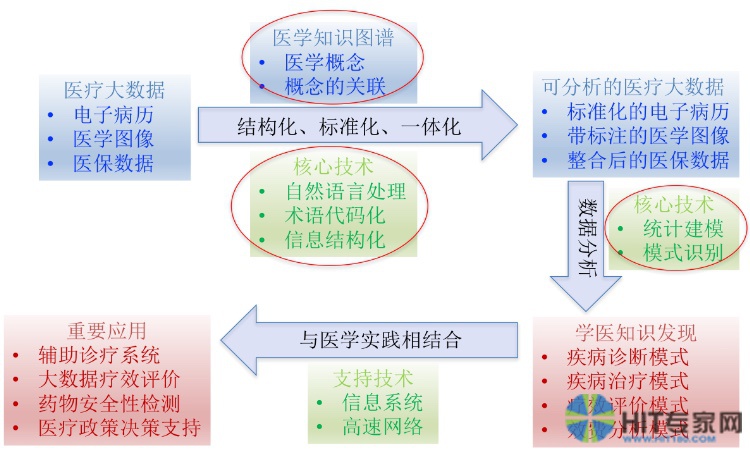
医疗大数据挖掘示意图
国内几乎每家医院的电子病历数量都非常大,医学文本分词和新词发现处理就是难点。虽然中文分析已经开发出了成功的方法和比较成熟的技术,但是过去的方法都趋于指导中文的分析。邓柯教授介绍了他们通过《人民日报》等新闻语料库拿到的训练数据加以训练的案例,从中提出很好的语法规则,再将这些信息全部整合起来建立模型。“当语料库和研究目标非常接近时,这些方法就会非常有效。”邓柯说。
但是,这方法应用在医学中就存在很大偏差。医生叙述的语言和《人民日报》的新闻语言有非常大的差别:第一,医学文本是具有领域独特性的中文,医生书写的医疗文本专业性很强,书写方式和语法结构都跟新闻不太一样;第二,不能够假定有一个很好的训练文本,因为医学问题里面新词和未知技术名词很多,很难假定有一个完整的词库。
邓柯介绍,还有一种传统成熟的文本分析方法叫主题模型(Topic Models),它的特性在于不关心文本当中细的信息,而关注粗糙的信息。所以当处理医疗文本,病历中所描述的病案、诊疗、服药等信息时,Topic Models应用也显得太粗糙了。
打破对语料库的依赖 开发无指导中文分析
为此,清华大学统计中心尝试着思考是否能够开发一种无指导的中文分析。
这一方法的基本原理是,在没有语料库和词库情况下,通过统计推断,做医学语言分析。该方法对于训练语料库没有依赖,对新词识别能力非常强,特别是对专有名词的分词做得很好。该方法的统计学基础非常清晰,整个过程建立在严格的统计分析和模型选择之上。此外,它运行非常快,几百万字的分析几分钟就能完成,还可以发现一些很低频的词汇。
据了解,清华统计中心和哈佛大学东亚文明系合作研究中国古代文献时就实践应用了无指导的中文分析方法。“我们尽可能地去收集中国历史上的文献、正史后,然后将它们整合起来,统筹处理这些数据。”邓柯解释说,古文、正史是独特的文本,形式复杂,写作风格、词句、语法变化很大,并且都有非常复杂的专有名词,这些特性跟医学用语是高度相似的。于是清华大学统计中心就借用这一方法应用于医学文本研究,目前效果还不错。如果再跟已有的医学知识进一步结合,研究效率还可以上一个台阶。由此可见,该方法对海量中文医学自然语言处理的初步分析和理解还是大有可为的。
引入统计推断法 实现医学文本标准化
从病历里将医学名词识别出来后,还要着力关注如何进行数据录入,如何杜绝录入错误,避免数据粘连,使医学文本最终能实现标准化。“这些都是难点,我们也在探索中。”邓柯说,清华大学统计中心跟国内某医院开展过合作,拿到该医院5%的抽样数据,其中住院病历有17万套,门诊病历有130万套。通过分析发现,很多病历只有疾病名称,住院病历和门诊病历录入中存在不少矛盾点。而且,即便是比较好的住院病历里面专有名称标准化也只占了60%不到,非标准化的占了40%。
为此,清华大学统计学研究中心尝试利用统计学推断方法去处理这一难点,这对不规范的医学数据识别、标准化有一定启示作用。邓柯认为,今后数据的积累都可以通过统计模型去做,让医务工作者不再去做问答题,而只需要做判断题和选择题,由此来提高效率。
“我们的团队期待着与医学专家碰出耀眼的火花。”邓柯说。
【专家简介】
邓柯,清华大学统计学研究中心副主任、副教授,入选“青年千人”计划。北京大学应用数学学士、统计学博士,哈佛大学博士后、副研究员。