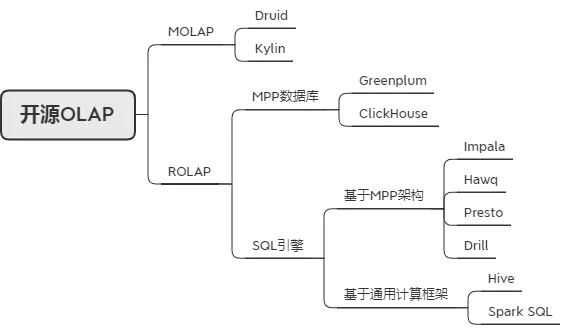
开源大数据OLAP组件,可以分为MOLAP和ROLAP两类。ROLAP中又可细分为MPP数据库和SQL引擎两类。对于SQL引擎又可以再细分为基于MPP架构的SQL引擎和基于通用计算框架的SQL引擎:

-
MOLAP一般对数据存储有优化,并且进行部分预计算,因此查询性能最高。但通常对查询灵活性有限制。 -> 关注清哥聊技术公众号,了解更多技术文章
-
MPP数据库是个完整的数据库,通常数据需要导入其中才能完成OLAP功能。MPP数据库在数据入库时对数据分布可以做优化,虽然入库效率有一定下降,但是对后期查询性能的提高有很大帮助。MPP数据库可以提供灵活的即席查询能力,但一般对查询数据量有一定限制,无法支撑特别大的数据量的查询。
-
SQL引擎只提供SQL执行的能力,本身一般不负责数据存储,通常可以对接多种数据储存,如HDFS、Hbase、MySQL等。有的还支持联邦查询能力,可以对多个异构数据源进行联合分析。SQL引擎中,基于MPP架构的SQL引擎,一般对在线查询场景有特殊优化,所以端到端查询性能一般要高于基于通用计算框架的SQL引擎;但是在容错性和数据量方面又会逊于基于通用计算框架的SQL引擎。
总之,可以说没有一个OLAP系统能同时在处理规模,灵活性和性能这三个方面做到完美,用户需要基于自己的需求进行取舍和选型。
2.1.1 Kylin
Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的 Hive 表。Kylin的核心思想是预计算,理论基础是:以空间换时间。即将多维分析可能用到的度量进行预计算,将计算好的结果保存成Cube并存储到Hbase中,供查询时直接访问。把高复杂度的聚合运算,多表连接等操作转换成对预计算结果的查询。

Kylin的核心模块:
-
REST Server:提供 Restful 接口,例如创建、构建、刷新、合并等 Cube 相关操作,Kylin 的 Projects、Tables 等元数据管理,用户访问权限控制,SQL 的查询等;
-
Query Engine:使用开源的 Apache Calcite 框架来实现 SQL 解析,可以理解为 SQL 引擎层;
-
Routing:负责将解析 SQL 生成的执行计划转换成 Cube 缓存的查询,这部分查询是可以在秒级甚至毫秒级完成;
-
metadata:Kylin 中有大量的元数据信息,包括 Cube 的定义、星型模型的定义、Job 和执行 Job 的输出信息、模型的维度信息等等,Kylin 的元数据和 Cube 都存储在 Hbase 中,存储的格式是 json 字符串;
-
Cube Build Engine:所有模块的基础,它主要负责 Kylin 预计算中创建 Cube,创建的过程是首先通过 Hive 读取原始数据,然后通过一些 MapReduce 或 Spark 计算生成 Htable,最后将数据 load 到 Hbase 表中。
整个系统分为两部分:
-
离线构建:
-
数据源在左侧,目前主要是 Hadoop Hive,保存着待分析的用户数据;
-
根据元数据的定义,下方构建引擎从数据源抽取数据,并构建 Cube;
-
数据以关系表的形式输入,支持星形模型和雪花模型;
-
2.5 开始 Spark 是主要的构建技术(以前是MapReduce);
-
构建后的 Cube 保存在右侧的存储引擎中,一般选用 Hbase 作为存储。
-
-
在线查询
-
用户可以从上方查询系统(Rest API、JDBC/ODBC)发送 SQL 进行查询分析;
-
无论从哪个接口进入,SQL 最终都会来到 Rest 服务层,再转交给查询引擎进行处理;
-
查询引擎解析 SQL,生成基于关系表的逻辑执行计划;
-
然后将其转译为基于 Cube 的物理执行计划;
-
最后查询预计算生成的 Cube 并产生结果。
-
- 优点:
-
亚秒级查询响应;
-
支持百亿、千亿甚至万亿级别交互式分析;
-
无缝与 BI 工具集成;
-
支持增量刷新;
- 缺点:
-
由于 Kylin 是一个分析引擎,只读,不支持 insert, update, delete 等 SQL 操作,用户修改数据的话需要重新批量导入(构建);
-
需要预先建立模型后加载数据到 Cube 后才可进行查询
-
使用 Kylin 的建模人员需要了解一定的数据仓库知识。
2.1.2 Druid
Apache Druid是高性能的实时分析数据库,主要提供对大量的基于时序的数据进行OLAP查询能力。支持毫秒级的快速的交互式查询。
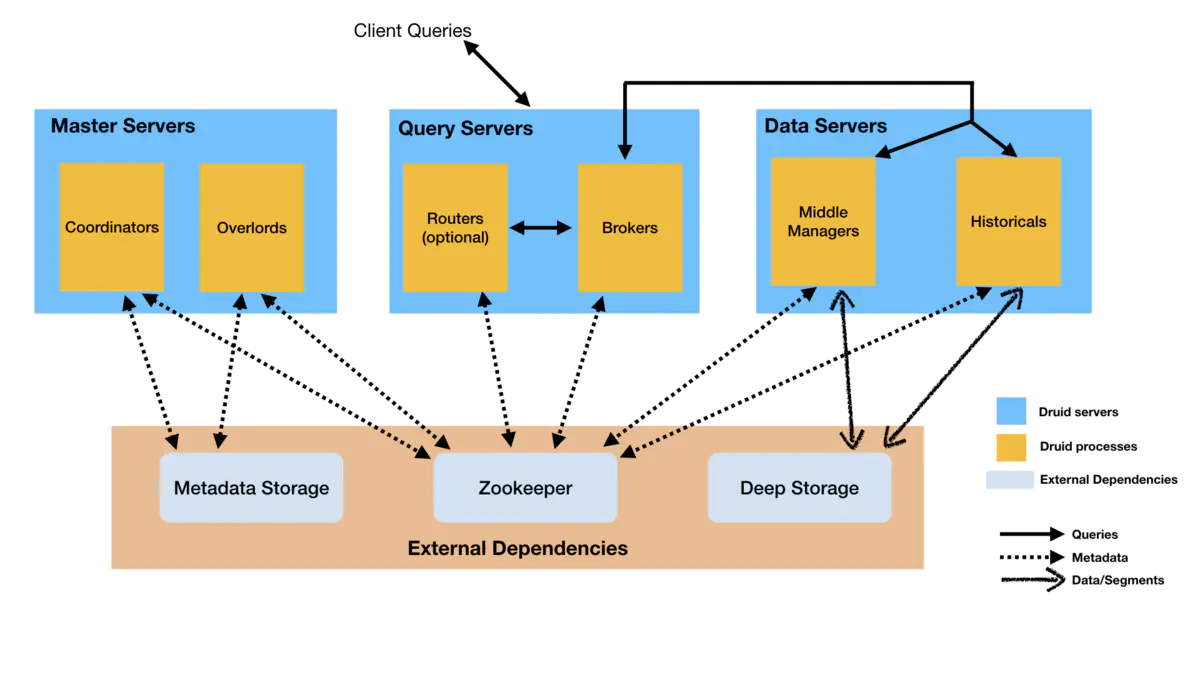
Druid有几种进程类型,简要描述如下:
-
Coordinators协调器进程:负责监控数据服务器上的Historicals进程,将Segments分配给特定的服务器,并负责确保Segments在多个Historicals之间保持平衡。
-
Overlords进程:负责监控数据服务器上的MiddleManager进程,并控制数据获取任务的分配。
-
Broker代理进程:处理来自外部客户端的查询,将查询转发给数据服务器去执行,并合并来自多个数据服务器的结果,返回给最终用户。
-
Routers进程:是个可选进程,提供统一的API Gateway,可以将请求路由到Brokers、Overlords和Coordinators。
-
Historicals进程:负责处理“历史数据”的查询。 它会从Deep Storage下载查询需要的Segments以加速查询。它不负责写入。
-
MiddleManager进程:负责处理获取到新数据,从外部数据源读取数据并转换成Segments进行存储。
Druid进程可以按照任何方式进行部署,但是为了易于部署,一般建议将它们组织为三种服务器类型:
-
主服务器:运行Coordinatos和Overlords进程,负责管理数据获取和数据可用性。
-
查询服务器:运行Brokers和可选的Routers进程,处理来自外部客户端的查询。
-
数据服务器:运行Historicals和MiddleManagers进程,负责执行数据获取任务并存储所有可查询的数据。
Druid之所以查询如此之快,与它针对多维数据优化的组织和存储方式有很大关系。它将数据索引存储在Segments文件中,Segment文件按列来存储,并通过时间分区来进行横向分割。Druid将数据列分为了三种不同的类型:

-
对于时间列和指标列处理比较简单,直接用lz4压缩存储。一旦查询知道去找哪几行,只需要将它们解压,然后用相应的操作符来操作它们就可以了。
-
对于维度列就没那么简单了,因为它们需要支持过滤和聚合操作,因此每个维度需要下面三个数据结构:
(1) 一个map,Key是维度的值,值是一个整型的id
(2) 一个存储列的值得列表,用(1)中的map编码的list
(3) 对于列中的每个值对应一个bitmap,这个bitmap用来指示哪些行包含这个个值。
为什么要使用这三个数据结构? map将字符串值映射为整数id,以便可以紧凑地表示(2)和(3)中的值。 (3)中的bitmap(也被称为倒排索引)允许快速过滤操作(特别地,bitmap便于快速进行AND和OR运算),这样,对于过滤再聚合的场景,无需访问(2)中的维度值列表。最后,(2)中的值可以被用来支持group by和TopN查询。
- 优点:
-
为分析而设计:为OLAP工作流的探索性分析而构建。它支持各种filter、aggregator和查询类型。
-
交互式查询:低延迟数据摄取架构允许事件在它们创建后毫秒内查询。
-
高可用:你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
-
可伸缩:每天处理数十亿事件和TB级数据。
- 缺点:
-
不支持更新操作,数据不可更改
-
不支持事实表之间的关联
2.2.1 Greenplum
GreenPlum是基于PostgreSQL的开源MPP数据库,具有良好的线性扩展能力,具有高效的并行运算和并行存储特性。
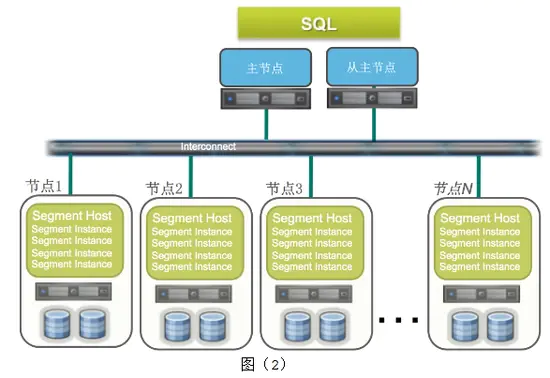
Greenplum的系统架构实际上是多台PostgreSQL数据库服务器组成的矩阵,采用无共享(no shareing)的MPP架构:
-
Master节点:作为数据库的入口,负责客服端连接;对客服端的请求生成查询计划,分发给某个或者所有的Segment节点。
-
Standby节点 : 作为master节点的备库,提供高可用性。
-
Interconnect:是GreenPlum的网络层;负责每个节点之间的通信。
-
Segment节点:为数据节点;接收master分发下来的查询计划;执行返回结果给master节点。
-
Mirror Segment节点: 作为Segment节点的备库,提供高可用性;通常跟对应的segment节点不在同一台机器上。
- 优点:
-
支持多态数据存储,允许用户根据应用定义数据分布方式,可提高查询性能。
-
具有高效的SQL优化器,针对OLAP查询进行优化。
- 缺点:
-
存在“木桶效应”,单机故障会导致性能严重下降,因此集群规模不能太大。
-
并发性能不高,通常无法支持超过30个并发。
2.2.2 ClickHouse
ClickHouse是Yandex(号称俄罗斯的‘百度’)开源的MPP架构的列式存储数据库。
目前ClickHouse公开的资料相对匮乏,比如在架构设计层面就很难找到完整的资料,甚至连一张整体的架构图都没有。
- ClickHouse为什么性能这么好?
-
着眼硬件。基于将硬件功效最大化的目的,ClickHouse会在内存中进行GROUP BY;与此同时,他们非常在意CPU L3级别的缓存,因为一次L3的缓存失效会带来70~100ns的延迟,意味着在单核CPU上,它会浪费4000万次/秒的运算。正因为注意了这些细节,所以ClickHouse在基准查询中能做到1.75亿次/秒的数据扫描性能。
-
注重算法。例如,在字符串搜索方面,针对不同的场景,ClickHouse选择了多种算法:对于常量,使用Volnitsky算法;对于非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2和hyperscan算法。除了字符串之外,其余的场景也与它类似,ClickHouse会使用最合适、最快的算法。如果世面上出现了号称性能强大的新算法,ClickHouse团队会立即将其纳入并进行验证。
-
特定场景,特殊优化。针对同一个场景的不同状况,选择使用不同的实现方式,尽可能将性能最大化。对于数据结构比较清晰的场景,会通过代码生成技术实现循环展开,以减少循环次数。
-
向量化执行。SIMD被广泛地应用于文本转换、数据过滤、数据解压和JSON转换等场景。相较于单纯地使用CPU,利用寄存器暴力优化也算是一种降维打击了。
- 优点:
- 速度快
- 缺点:
-
不支持事务,不支持真正的删除/更新;
-
不支持高并发,Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行。
-
join性能不高
-
开源社区主要是俄语为主.
2.3.1 Presto
Presto是Facebook推出分布式SQL交互式查询引擎,完全基于内存的并行计算,支持任意数据源,数据规模GB~PB。

Presto采用典型的Master-Slave架构:
-
coordinator:是presto集群的master节点。负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。
-
worker:是执行任务的节点。负责实际查询任务的计算和读写。
-
discovery service:是将coordinator和worker结合在一起服务。worker节点启动后向discovery service服务注册,coordinator通过discovery service获取注册的worker节点。
-
connector:presto以插件形式对数据存储层进行了抽象,即connector。可通过connector连接多种数据源,提取数据。
discovery service 将coordinator和worker结合在一起服务; worker节点启动后向discovery service服务注册 coordinator通过discovery service获取注册的worker节点
既然Presto是一个交互式的查询引擎,我们最关心的就是Presto实现低延时查询的原理,我认为主要是下面几个关键点:
-
完全基于内存的并行计算
-
流水线式计算作业
-
本地化计算
-
动态编译执行计划
-
小心使用内存和数据结构
-
类BlinkDB的近似查询
-
GC控制
-
与Hive的比较:
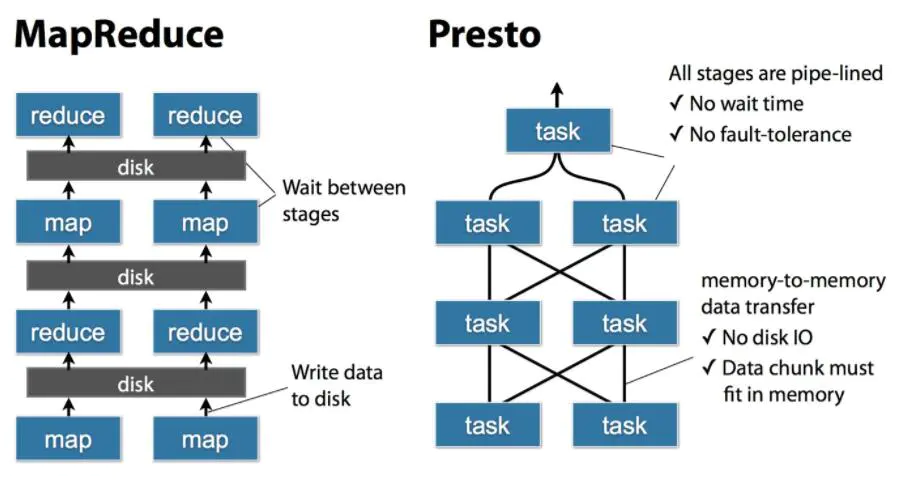
上图显示了MapReduce与Presto的执行过程的不同点,MR每个操作要么需要写磁盘,要么需要等待前一个stage全部完成才开始执行,而Presto将SQL转换为多个stage,每个stage又由多个tasks执行,每个tasks又将分为多个split。所有的task是并行的方式进行允许,stage之间数据是以pipeline形式流式的执行,数据之间的传输也是通过网络以Memory-to-Memory的形式进行,没有磁盘io操作。这也是Presto性能比Hive快很多倍的决定性原因。
-
与Spark的比较:
-
目标:Presto强调查询,但Spark重点强调计算。
-
架构:Presto的体系结构与MPP SQL引擎非常相似。这意味着仅针对SQL查询执行进行了高度优化,而Spark是一个通用执行框架,能够运行多个不同的工作负载,如ETL,机器学习等。
-
任务启动:Presto的查询没有太多开销。Presto协调器始终处于启动状态并等待查询。而Spark驱动程序启动需要时间与集群管理器协商资源,复制jar,才开始处理。
-
任务提交:Spark提交任务并在每个阶段实时应用资源(与presto相比,这种策略可能导致处理速度稍慢); Presto一次申请所需资源,并且一次提交所有任务。
-
数据处理:在spark中,数据需要在进入下一阶段之前完全处理。 Presto是流水线式处理模式。只要一个page完成处理,就可以将其发送到下一个task(这种方法大大减少了各种查询的端到端响应时间)。
-
内存:两者都是内存存储和计算,当它无法获得足够的内存时,spark会将数据写入磁盘,但presto会导致OOM。
-
容错:如果Spark任务失败或数据丢失,它将重新计算。但是presto会导致查询失败。
-
-
优点:
-
基于内存运算,减少没必要的硬盘IO,所以快。
-
都能够处理PB级别的海量数据分析。(虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。)
-
能够连接多个数据源,跨数据源关联查询。
-
清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。部署简单。
- 缺点:
-
不适合多个大表的join操作,因为presto是基于内存的,太多数据内存放不下的。
-
Presto的一个权衡是不关心中间查询容错。如果其中一个Presto工作节点出现故障(例如,关闭),则大多数情况下正在进行的查询将中止并需要重新启动。
2.3.2 HAWQ
HAWQ是Pivotal公司开源的一个Hadoop原生大规模并行SQL分析引擎,针对的是分析型应用。Apache HAWQ 采用主从(Master-Slave)的改进MPP架构,通过将MPP与批处理系统有效的结合,克服了MPP的一些关键的限制问题,如短板效应、并发限制、扩展性等。其整体架构与Pivotal另一开源MPP数据库Greenplum比较相似:

HAWQ Master节点内部有以下几个重要组件:
-
查询解析器(Parser/Analyzer),负责解析查询,并检查语法及语义。最终生成查询树传递给优化器。
-
优化器(Optimizer),负责接受查询树,生成查询计划。针对一个查询,可能有数亿个可能的等价的查询计划,但执行性能差异很大。优化器的做用是找出优化的查询计划。
-
资源管理器(Resource Manager),资源管理器经过资源代理向全局资源管理器(好比YARN)动态申请资源。并缓存资源。在不须要的时候返回资源。
-
HDFS元数据缓存(HDFS Catalog Cache),用于HAWQ确定哪些Segment扫描表的哪些部分。HAWQ是把计算派发到数据所在的地方。因此要匹配计算和数据的局部性。如果每一个查询都访问HDFS NameNode会形成NameNode的瓶颈。因此在HAWQ Master节点上创建了HDFS元数据缓存。
-
容错服务(Fault Tolerance Service),负责检测哪些节点可用,哪些节点不可用。不可用的机器会被排除出资源池。
-
查询派遣器(Dispatcher),优化器优化完查询之后,查询派遣器派遣计划到各个节点上执行,并协调查询执行的整个过程。查询派遣器是整个并行系统的粘合剂。
-
元数据服务(Catalog Service),负责存储HAWQ的各类元数据,包括数据库和表信息,以及访问权限信息等。另外,元数据服务也是实现分布式事务的关键。
其余节点为Slave节点。每一个Slave节点上部署有HDFS DataNode,YARN NodeManager以及一个HAWQ Segment。HAWQ Segment在执行查询的时候会启动多个QE (Query Executor, 查询执行器)。查询执行器运行在资源容器里面。节点间数据交换经过Interconnect(高速互联网络)进行。
- 优点:
-
对SQL标准的完善支持:ANSI SQL标准,OLAP扩展,标准JDBC/ODBC支持。
-
支持ACID事务特性:这是很多现有基于Hadoop的SQL引擎做不到的,对保证数据一致性很重要。
-
动态数据流引擎:基于UDP的高速互联网络。
-
多种UDF(用户自定义函数)语言支持:java, python, c/c++, perl, R等。
-
动态扩容:动态按需扩容,按照存储大小或者计算需求,秒级添加节点。
-
支持MADlib机器学习。
- 缺点:
-
基于GreenPlum实现,技术实现复杂,包含多个组件。比如对于外部数据源,需要通过PXF单独进行处理;
-
C++实现,对内存的控制比较复杂,如果出现segmentfault直接导致当前node挂掉。
-
安装配置复杂;
2.3.3 Impala
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具。
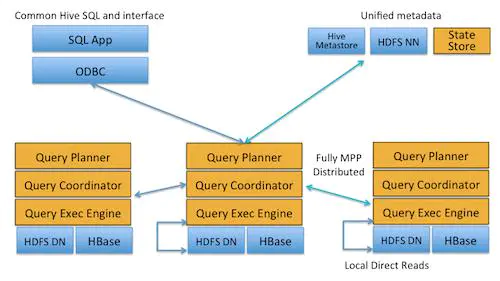
Impala采用MPP架构,与存储引擎解耦:
-
impalad(实例*N): 接收client、hue、jdbc或者odbc请求。每当将查询提交到特定节点上的impalad时,该节点充当该查询的“协调器节点”,负责将Query分发到其他impalad节点来并行化查询,所有查询结果返回给中心协调节点。
-
StateStore(实例*1): 负责收集分布在各个Impalad进程的资源信息、各节点健康状况,同步节点信息;
-
Catalog Service(实例*1): 分发表的元数据信息到各个Impalad中,每个Impala节点在本地缓存所有元数据。
-
与Hive的比较:
Impala 与Hive都是构建在Hadoop之上的数据查询工具,各有不同的侧重点, Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。
-
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, Hbase。
-
元数据:两者使用相同的元数据。
-
SQL解释处理:比较相似都是通过词法分析生成执行计划。
-
执行计划:
-
Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
-
Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
-
-
数据流:
-
Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
-
Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
-
-
内存使用:
-
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
-
Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存。这使用得Impala目前处理Query会受到一 定的限制。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
-
-
调度:
-
Hive: 任务调度依赖于Hadoop的调度策略。
-
Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器目前还比较简单,还没有考虑负载,网络IO状况等因素进行调度。但目前 Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
-
-
容错:
-
Hive: 依赖于Hadoop的容错能力。
-
Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败, 再查一次就好了,再查一次的成本很低)。
-
-
适用面:
-
Hive: 复杂的批处理查询任务,数据转换任务。
-
Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制。
-
-
-
优点:
-
支持SQL查询,快速查询大数据。
-
可以对已有数据进行查询,减少数据的加载,转换。
-
多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
-
可以与Hive配合使用。
-
-
缺点:
-
不支持用户定义函数UDF。
-
不支持text域的全文搜索。
-
不支持Transforms。
-
不支持查询期的容错。
-
对内存要求高。
-
2.3.4 Drill
Drill是MapR开源的一个低延迟的大数据集的分布式SQL查询引擎,是谷歌Dremel的开源实现。它支持对本地文件、HDFS、Hbase等数据进行数据查询,也支持对如JSON等schema-free的数据进行查询。
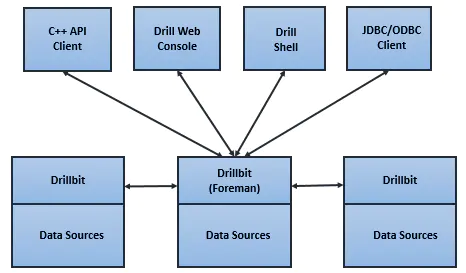
从架构上看,与同是源自Dremel的Impala比较类似。Drill的核心是DrillBit,它主要负责接收客户端的请求,处理查询,并将结果返回给客户端。 Drill的查询流程包括以下步骤:
-
Drill客户端发起查询,任意DrilBit都可以接受来自客户端的查询
-
收到请求的DrillBit成为驱动节点(Foreman),对查询进行分析优化生成执行计划,之后将执行计划划分成各个片段(Fragment),并确定合适的节点来执行。
-
各个节点执行查询片段(Fragment),并将结果返回给驱动节点
-
驱动节点将结果返回给客户端
- 优点:
-
能够自动解析数据(json,text,parquet)的结构。
-
支持自定义的嵌套数据集,数据灵活,,支持查询复杂的半结构化数据。
-
与Hive一体化(Hive表和视图的查询,支持所有的Hive文件格式和HiveUDFS)。
-
支持多数据源,包括NoSQL数据库。
-
可以方便的与第三方BI工具对接。
- 缺点:
-
SQL语法和常规SQL有区别,一般是如“select * from 插件名.表名”的形式。
-
安装部署比较复杂。
-
GC机制还有待提高。
2.4.1 SparkSQL
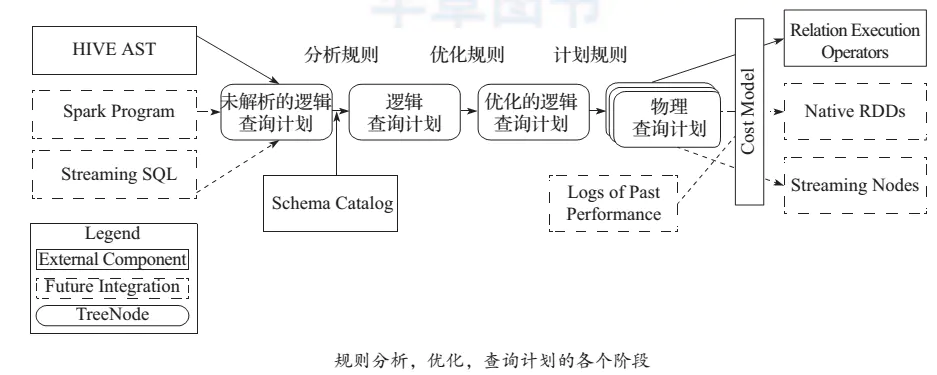
Spark SQL与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎:

Spark SQL 的查询优化是Catalyst,Catalyst 将 SQL 语言翻译成最终的执行计划,并在这个过程中进行查询优化。这里和传统不太一样的地方就在于, SQL 经过查询优化器最终转换为可执行的查询计划是一个查询树,传统 DB 就可以执行这个查询计划了。而 Spark SQL 最后执行还是会在 Spark 内将这棵执行计划树转换为 Spark 的有向无环图DAG 再执行。
- 优点:
-
将sql查询与spar无缝融合
-
兼容HiveQL
- 缺点:
-
查询性能不高
-
以thrift server方式提供的SparkSQL服务不支持多种数据源,必须使用Dataframe API。
2.4.2 Hive
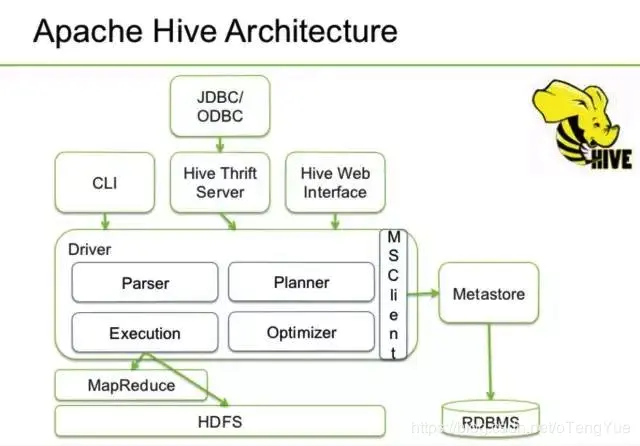
Hive是一个构建于Hadoop顶层的数据仓库工具。定义了简单的类似SQL 的查询语言——HiveQL,可以将HiveQL查询转换为MapReduce 的任务在Hadoop集群上执行。
- 优点:
-
高可靠、高容错:HiveServer采用集群模式。双metaStor。超时重试机制。
-
类SQL:类似SQL语法,内置大量函数。
-
可扩展:自定义存储格式,自定义函数。
-
多接口:Beeline,JDBC,ODBC,Python,Thrift。
- 缺点:
-
延迟较高:默认MR为执行引擎,MR延迟较高。
-
不支持物化视图:Hive支持普通视图,不支持物化视图。Hive不能再视图上更新、插入、删除数据。
-
不适用OLTP:暂不支持列级别的数据添加、更新、删除操作。
测试数据来源于:开源OLAP引擎测评报告。通过测试以及相关调研编写了各组件各个方面的综合对比分析表,这里采用5分为满分来比较,如下表:
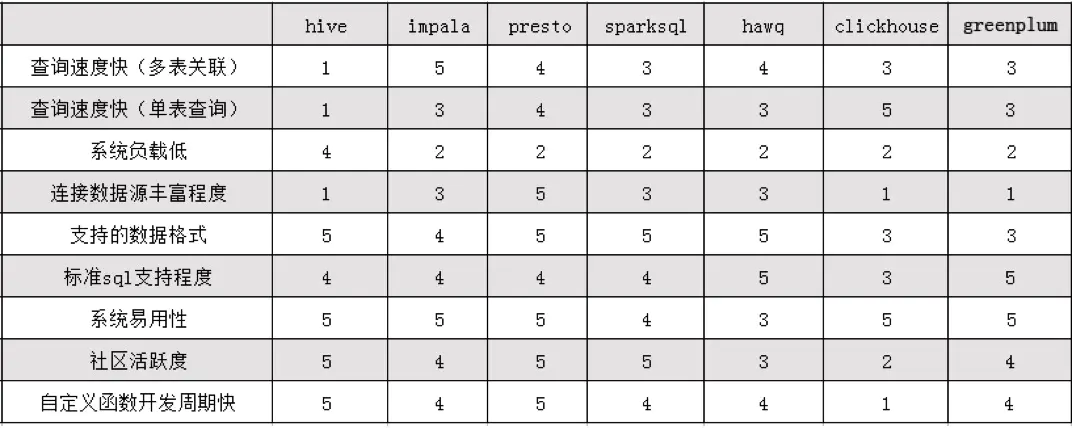
-
SparkSQL是Hadoop中另一个著名的SQL引擎,它以Spark作为底层计算框架,Spark使用RDD作为分布式程序的工作集合,它提供一种分布式共享内存的受限形式。在分布式共享内存系统中,应用可以向全局地址空间的任意位置进行读写作,而RDD是只读的,对其只能进行创建、转化和求值等作。这种内存操作大大提高了计算速度。SparkSql的性能相对其他的组件要差一些,多表单表查询性能都不突出。
-
Impala官方宣传其计算速度是一大优点,在实际测试中我们也发现它的多表查询性能和presto差不多,但是单表查询方面却不如presto好。而且Impala有很多不支持的地方,例如:不支持update、delete操作,不支持Date数据类型,不支持ORC文件格式等等,所以我们查询时采用parquet格式进行查询,而且Impala在查询时占用的内存很大。
-
Presto综合性能比起来要比其余组件好一些,无论是查询性能还是支持的数据源和数据格式方面都要突出一些,在单表查询时性能靠前,多表查询方面性能也很突出。由于Presto是完全基于内存的并行计算,所以presto在查询时占用的内存也不少,但是发现要比Impala少一些,比如多表join需要很大的内存,Impala占用的内存比presto要多。
-
HAWQ 吸收了先进的基于成本的 SQL 查询优化器,自动生成执行计划,可优化使用hadoop 集群资源。HAWQ 采用 Dynamic pipelining 技术解决这一关键问题。Dynamic pipelining 是一种并行数据流框架,利用线性可扩展加速Hadoop查询,数据直接存储在HDFS上,并且其SQL查询优化器已经为基于HDFS的文件系统性能特征进行过细致的优化。但是我们发现HAWQ在多表查询时比Presto、Impala差一些;而且不适合单表的复杂聚合操作,单表测试性能方面要比其余四种组件差很多,hawq环境搭建也遇到了诸多问题。
-
ClickHouse 作为目前所有开源MPP计算框架中计算速度最快的,它在做多列的表,同时行数很多的表的查询时,性能是很让人兴奋的,但是在做多表的join时,它的性能是不如单宽表查询的。性能测试结果表明ClickHouse在单表查询方面表现出很大的性能优势,但是在多表查询中性能却比较差,不如presto、impala、hawq的效果好。
-
以上就是本篇文章【【转载】大数据OLAP系统--开源组件方案对比】的全部内容了,欢迎阅览 ! 文章地址:http://sjzytwl.xhstdz.com/quote/80096.html 栏目首页 相关文章 动态 同类文章 热门文章 网站地图 返回首页 物流园资讯移动站 http://mip.xhstdz.com/ , 查看更多